We’ll now start writing the tokenizer.
One thing I haven’t explained yet is how we will deal with white-space. The easiest solution is to just skip the white-space between tokens, and that’s what we’ll do. Usually white-space is defined as one of the following characters: space (' '), tab ('\t'), new-line ('\n') or carriage-return ('\r'). But I noticed that any character below space (' ') is never used as text. So we can just consider any character ≤ ' ' to be white-space, which makes it easier to test a character.
Because we want our tokenizer to read characters from strings as well as streams, we’ll use a TextReader. TextReader has 2 derived classes: StringReader (to read text from a string) and StreamReader (to read text from a stream). The only method in TextReader we will use is Read(), which returns the next character or -1 if the end of the stream or string has been reached.
To extract a token, we read the first character and decide what type of token it will be. For each token, we will have to store the characters it contains. We’ll use a StringBuilder for this.
using System;
using System.Collections.Generic;
using System.Text;
using System.IO;
namespace TC.Adl
{
public class Tokenizer
{
private readonly TextReader _source;
private char _currentChar;
private readonly StringBuilder _tokenValueBuffer;
}
}
Our Tokenizer class has only 3 fields:
- _source: the TextReader to read characters from.
- _currentChar: the current character (most recently read).
- _tokenValueBuffer: the StringBuilder to store the characters of the current token.
The constructor of the Tokenizer class will accept a TextReader argument, store it in _source, initialize _tokenValueBuffer and read the first character:
public Tokenizer(TextReader source)
{
if (source == null) throw new ArgumentNullException("source");
_source = source;
_tokenValueBuffer = new StringBuilder();
ReadNextChar();
}
Now we’ll add some private helper methods.
Reading a character is simple. Just call TextReader.Read(), which returns an int. Because a char cannot be -1 (which is returned by TextReader.Read() at the end of the text), we will use character '\0' as the end-of-stream character.
private void ReadNextChar()
{
int c = _source.Read();
if (c > 0)
{
_currentChar = (char)c;
}
else
{
_currentChar = '\0';
}
}
Skipping white-space is also easy: just keep reading characters until we get a character that is not white-space:
private void SkipWhitespace()
{
while (_currentChar > '\0' && _currentChar <= ' ')
{
ReadNextChar();
}
}
To determine if we’re at the end of the source, we just have to check the current character for '\0':
private bool AtEndOfSource
{
get { return _currentChar == '\0'; }
}
We’ll also write a simple method to store the current character and read the next:
private void StoreCurrentCharAndReadNext()
{
_tokenValueBuffer.Append(_currentChar);
ReadNextChar();
}
And a method to extract the stored characters and clear the buffer:
private string ExtractStoredChars()
{
string value = _tokenValueBuffer.ToString();
_tokenValueBuffer.Length = 0;
return value;
}
Because the source code can have errors, we’ll need some methods that throw exceptions:
private void CheckForUnexpectedEndOfSource()
{
if (AtEndOfSource)
{
throw new ParserException("Unexpected end of source.");
}
}
private void ThrowInvalidCharException()
{
if (_tokenValueBuffer.Length == 0)
{
throw new ParserException("Invalid character '" + _currentChar.ToString() + "'.");
}
else
{
throw new ParserException(
"Invalid character '" + _currentChar.ToString()
+ "' after '" + _tokenValueBuffer.ToString() + "'.");
}
}
Which introduces our ParserException class (a standard Exception sub-class):
using System;
using System.Collections.Generic;
using System.Text;
using System.Runtime.Serialization;
namespace TC.Adl
{
[Serializable]
public class ParserException : Exception
{
public ParserException() { }
public ParserException(string message) : base(message) { }
public ParserException(string message, Exception innerException) : base(message, innerException) { }
protected ParserException(SerializationInfo info, StreamingContext context) : base(info, context) { }
}
}
Now that we’ve written the private helper methods, we can write the only public method: the ReadNextToken method. This method reads a token and returns it. First we skip the initial white-space. If we reach the end of the source, we return null; else we check the first character to determine the type of token:
- if the token starts with a letter, it’s a word
- if the token starts with a digit, it’s an integer constant
- if the token starts with a double quote, it’s a string constant
- if it’s any other character, we assume it’s a symbol
public Token ReadNextToken()
{
SkipWhitespace();
if (AtEndOfSource)
{
return null;
}
if (char.IsLetter(_currentChar))
{
return ReadWord();
}
if (char.IsDigit(_currentChar))
{
return ReadIntegerConstant();
}
if (_currentChar == '"')
{
return ReadStringConstant();
}
return ReadSymbol();
}
A word starts with a letter (already tested in ReadNextToken), followed by 0 or more letters or digits. So all we have to do is keep reading until we reach a character that is not a letter or digit:
private Token ReadWord()
{
do
{
StoreCurrentCharAndReadNext();
}
while (char.IsLetterOrDigit(_currentChar));
return new Token(TokenType.Word, ExtractStoredChars());
}
An integer constant just contains digits:
private Token ReadIntegerConstant()
{
do
{
StoreCurrentCharAndReadNext();
}
while (char.IsDigit(_currentChar));
return new Token(TokenType.Integer, ExtractStoredChars());
}
A string constant contains a sequence of characters, enclosed in quotes. Because the quote character is used as a delimiter, the characters in between cannot be quotes. But all other characters are allowed. If the end of the source is reached before the closing quote, we throw an exception. We don’t want the quotes to be included in the value of the token, so we skip them with ReadNextChar.
private Token ReadStringConstant()
{
ReadNextChar();
while (!AtEndOfSource && _currentChar != '"')
{
StoreCurrentCharAndReadNext();
}
CheckForUnexpectedEndOfSource();
ReadNextChar();
return new Token(TokenType.String, ExtractStoredChars());
}
Reading a symbol is more complicated. A symbol can be one or two characters, so we have to treat each case individually:
private Token ReadSymbol()
{
switch (_currentChar)
{
case '+':
case '-':
case '*':
case '/':
case '(':
case ')':
case ',':
// the symbols + - * / ( ) ,
StoreCurrentCharAndReadNext();
return new Token(TokenType.Symbol, ExtractStoredChars());
case ':':
case '=':
// the symbols := ==
StoreCurrentCharAndReadNext();
if (_currentChar == '=')
{
StoreCurrentCharAndReadNext();
return new Token(TokenType.Symbol, ExtractStoredChars());
}
CheckForUnexpectedEndOfSource();
ThrowInvalidCharException();
break;
case '<':
// the symbols < <> <=
StoreCurrentCharAndReadNext();
if (_currentChar == '>' || _currentChar == '=')
{
StoreCurrentCharAndReadNext();
}
return new Token(TokenType.Symbol, ExtractStoredChars());
case '>':
// the symbols > >=
StoreCurrentCharAndReadNext();
if (_currentChar == '=')
{
StoreCurrentCharAndReadNext();
}
return new Token(TokenType.Symbol, ExtractStoredChars());
default:
CheckForUnexpectedEndOfSource();
ThrowInvalidCharException();
break;
}
return null;
}
That’s it, our Tokenizer class is done. To test it, we’ll write a small application. Add a new Form to the project TC.Adl.Test, named TokenizerTest. It will have a multiline TextBox where we can type in source code (TextBoxSource), a Button to tokenize the source code (ButtonTokenize), and a ListBox that will display the tokens (ListBoxTokens). It should look like this:
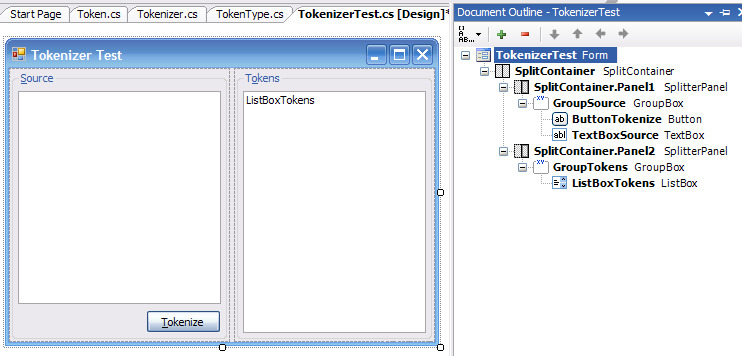
The Click event handler of the button creates a new Tokenizer, reads all the tokens, and adds them to the ListBox:
private void ButtonTokenize_Click(object sender, EventArgs e)
{
ListBoxTokens.Items.Clear();
ListBoxTokens.BeginUpdate();
try
{
using (StringReader source = new StringReader(TextBoxSource.Text))
{
Tokenizer tokenizer = new Tokenizer(source);
Token token = tokenizer.ReadNextToken();
while (token != null)
{
ListBoxTokens.Items.Add(token.Type.ToString() + ":\t" + token.Value);
token = tokenizer.ReadNextToken();
}
}
}
catch (ParserException exception)
{
MessageBox.Show(this, exception.Message, this.Text, MessageBoxButtons.OK, MessageBoxIcon.Error);
}
finally
{
ListBoxTokens.EndUpdate();
}
}
Now you can start the application, run the TokenizerTest and try out some code to see what tokens are generated. Try out this sample:
for i := 1 to 100 do
if i < 50 then
print(i, " < 50")
else
print(i, " >= 50")
end if
end for
As you can see, converting characters to tokens is not very complicated. You just have to get used to it.